
公司动态
AI传记伪影释放视频模型
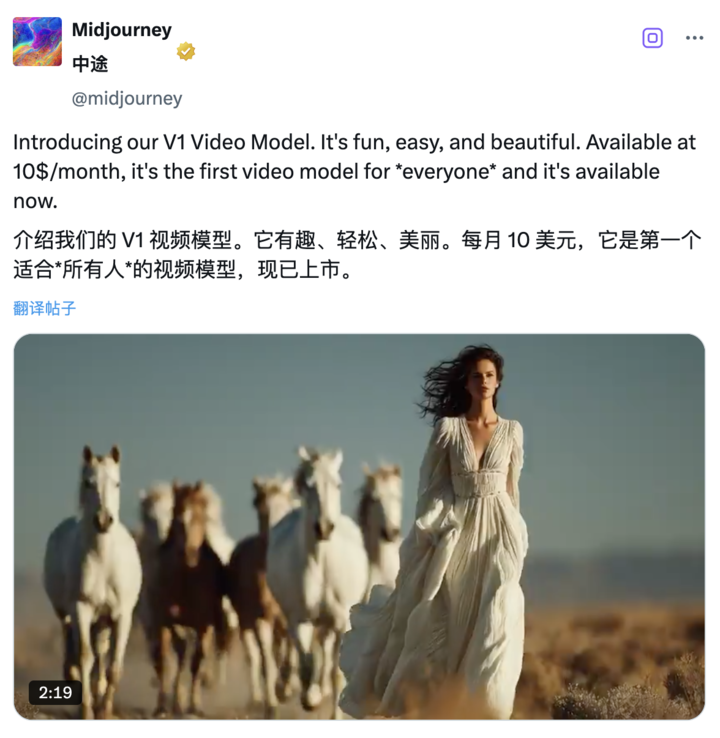 面对迪士尼和环球影业之间的版权西装,资深文学和文化照片“独角兽”米朱尼(Midjourney)并没有放慢脚步,而是在今年清晨在压力下推出了第一个视频模型。颜色调整是准确的,构图是独特的,完整的,并且样式仍然在线。不受控制的分辨率,不受控制的长镜头和Midjourney卷是一种独特的环境和审美识别的感觉。 Midjourney雄心勃勃,针对“世界模型”,但是当前的略微“粗糙”设计可能是未知的。保存版本如下:上传或开发图像后,单击“动画”。可以实现默认一个任务中4个5秒视频的默认输出,并且最大长度可以扩展到21秒。支持两种模式模式,用户可以通过立即单词来设置屏幕生成的效果;提供低运动选择和高运动S,适用于静态环境或强大的动态视频场景功能,现有订阅($ 10/月)。 GPU资源消耗是图像任务的8倍。它不支持添加声音效果,时间表编辑,移动剪辑或访问API。该分辨率仅为480p,该方面的方面自动适应图像。这仍然是视频模型的早期版本。它将将来继续推出。将启动3D和实时系统模型,最终目标是打开世界模型环境。 V ModelMidjourney的想法正式启动。您滚动了解决方案,然后我去了超现实。 Midjourney一直以其幻想和超现实的视觉风格而闻名。从用户的实际结果来看,其视频模型也以稳定的风格和高知名度继续沿着这个美学方向发展。在Blogger @eccentrismart共享的视频中,一个少年垂直落下高度。该角色具有简单的形状和强烈的动态新感觉,例如在梦中跳跃,自由落下或自由落下,运动道路平稳,角色重力的特征很自然。城市块是密集的,灯光密集,建筑物似乎在太空中倾斜和旋转,形成了空间中的失真幻象,但是一般的动态NG建筑物并没有颤抖,或者AI会产生分隔错误;在这个日本电台站的视频站,当电车离开车站时,太阳将无法落下,在该区域中控制着色温,而光资源是自然的;创建一种节奏,使静态并掩盖运动。 ▲提示:火车穿过车站。 | @pjaccetturo穿着衬衫的女人的轮廓,手里拿着文件或书。在他身后是人头的大剪影。可以看出,将处理许多曝光/分层组成,并使用自然而没有过多的过量。 AI设计师Phi Hoang的损失表示超出了预期,这并不奇怪。著名的X Blogger @NickFloat分享了一个在马拉瓦纳格轻轨平台上行走的女孩的视频。有一列火车在背景中经过高速,具有明显的光线和阴影分区和强烈的三维性。夜晚,诸如雪,大灯和运动运动等元素的极光统一为视频生成模型带来了很大的挑战。但是,该模型成功地处理了许多轻度干扰。雪颗粒,模糊的车速和轨迹光效率的强劲一致性。 ▲提示:2022年世界拉力蓝色斯巴鲁,夜间芬兰赛车,戏剧性动作拍摄,动态运动模糊,雪飞,天空上的北极光,雪地灯,高柜台,高柜台,电影照明| @jamiegerard穿着经典的空间西装,大量五颜六色的轨迹在宇航员后面延伸的奥里斯(Ories),表现出一种幻想的“旅行”或“高速运动”,具有强烈的视觉节奏感。 ▲提示:“活了一点,掉了酸,我飞了一飞行中的宇航员,我认为这不会造成他们像太空中的宇航员一样的伤害” | @jamiagerard,材料,流体运动和其他元素的亮点是窗口,以查看AI模型的表达。在此视频中,冰,奶油和焦糖是动态而自然的,标签不会打扰杯子。 ▲提示:星巴克饮料,经典的高杯,冰焦糖Macchiato,旋转焦糖毛毛雨,顶部鲜奶油,杯子冷凝,浓郁和开胃的高品质饮料,1:1的方面。 | @JamiaGeerard具有清晰的视角,适当的位置和近距离的意识,并且具有强烈的耐受性效果。 ▲提示:坐在丛林的中间,许多野生动物在S | @jamiagerard新的Yor感觉K的世界末日街道,有足够的细节,例如燃烧的汽车和损坏;根据直接单词的要求,生成的视频需要具有35mm的胶片质地,通常也有略微谷物。 ▲提示:清晨的一条城市街道,燃烧的汽车和嘴唇散落在各处。现场是由1990年代纽约发行的,以摄影师杰夫·沃尔(Jeff Wall)的风格捕捉,并带有35毫米胶卷的粒状质地。 | @jamiagerard水晶球正在慢慢转过身,放慢速度,尝试场景的稳定性,相机的移动相对稳定。 ▲提示:结晶球盘旋并缓慢旋转在平静的彩色田野上方,稳定的凸轮射击| @jamiagerard值得注意的是,上面显示的情况的产生结果可能会经过许多“卡绘制”,但是就最终效果而言,视觉完成相对较大。雄心勃勃的Midjourney建立了第二个“世界模型”构件。来自nOWE,Midjourney用户可以将图像上传到官方网站(Midjourney.com),或直接使用平台生成的图像,单击“动画”按钮将图像转换为视频。每个任务都将开发4个5秒视频。用户每次添加4秒钟,总持续时间最多可扩展到4次,并且总持续时间最多为21秒。当然,很难从一千千步开始,该官员表示将来将进一步扩大它的持续时间和功能。操作逻辑阈值确实不高。您可以像以前一样在Midjourney创建图像,但是现在有一个额外的步骤来传输图片。此外,您可以将外部图像作为“开始框架”上传,然后使用及时的单词来描述要显示的动态 - 新效果。 V1提供了一些可调节的自定义设置,以促进用户进行更详细的屏幕内容控制。在“ Manu -Manong”中,您可以输入特定单词以自动设置视频元素的移动和开发场景的过程,但是如果您目前不知道即时单词,则可以选择“自动”设置,该设置会自动为您开发单词单词并进行图像传输。在创意风格方面,您还可以选择两种动力设置:低运动:适用于环境场景,镜头通常保持静止,主题移动缓慢或肿胀。缺点是,有时它根本无法移动(例如角色)闪烁,微风盛开等);高动作:适用于镜头和主题非常移动的场景。缺点是强烈的运动有时会导致照片或不兼容的错误。在价格方面,视频操作直接包含在Midjourney订阅系统中,并且起价仍然为每月10美元。根据官方博客,只要IM的工作年龄,但每秒平均成本与图像的产生非常相似,前提是可以形成视频器长达20秒。与竞争对手相比,成本效益可以对第一个梯队进行排名。我们还使用AI搜索引擎简要对您的参考的一些基本视频模型进行了简要分类,而Midjourney则尝试以较慢的速度完成“放松模式”,以降低计算源的消耗,以便以较慢的速度完成语言任务。至于其他级别的用户,仍将根据GPU时间和会员资格级别收费。当前,有很多值得抱怨的是Midjourney录像模型,最常见的功能是缺乏一些专业创作的基本技能。首先,与Dreamveo 3或Old的Dream Machine不同,Midjourney视频模型不支持自动添加背景音乐或环境音效。如果您需要音频,您仍然需要与其他t一起手动添加Hird Party工具。其次,Midjourney视频模型不支持编辑时间,而生成的视频片段“跳跃”,并且无法实现图片之间的持续故事和自然连接,因此很难控制框架的节奏或情感准备。此外,MidJourney视频模型现在无法提供对API的访问。更重要的是,Midjourney生成的默认视频分辨率为480p(常识),并且根据原始图像大小自动对视频纵横比自动调整,并且在上传到其他平台时也可以标记为480p。 ▲注意:可以通过Midjourney稍微固定。方面的比率稍微固定,最终输出视频可能与起始图像略有不同。 Midjourney官员还承认,当前版本处于探索的早期阶段,专注于访问,易于使用和测量。视频模型只是一个切口,而Midjourney想要的是一个更完整的内容人ufacture系统。根据其官方计划,最终目标是开发“世界模型”,即包括图像生成,动画控制,三维空间导航和实时渲染。您可以理解,在可以实时制作照片的AI系统中,输入句子并订购了AI的主角进入3D空间,环境中的场景也会改变,您可以联系所有内容。为了实现这一目标,kyou将需要图像模型(生成静态图片)→视频模型(让绘画)移动表面)→3D模型(以实现空间导航和镜头运动)→实时模型(以确保每个帧可以响应同步)。根据Midjourney产品计划,这四个技术“构建块”将交付到接下来的12个月中,并最终将包含在一个系统中。 V1视频模型是一个分阶段,是最终果阿的第二步l。
面对迪士尼和环球影业之间的版权西装,资深文学和文化照片“独角兽”米朱尼(Midjourney)并没有放慢脚步,而是在今年清晨在压力下推出了第一个视频模型。颜色调整是准确的,构图是独特的,完整的,并且样式仍然在线。不受控制的分辨率,不受控制的长镜头和Midjourney卷是一种独特的环境和审美识别的感觉。 Midjourney雄心勃勃,针对“世界模型”,但是当前的略微“粗糙”设计可能是未知的。保存版本如下:上传或开发图像后,单击“动画”。可以实现默认一个任务中4个5秒视频的默认输出,并且最大长度可以扩展到21秒。支持两种模式模式,用户可以通过立即单词来设置屏幕生成的效果;提供低运动选择和高运动S,适用于静态环境或强大的动态视频场景功能,现有订阅($ 10/月)。 GPU资源消耗是图像任务的8倍。它不支持添加声音效果,时间表编辑,移动剪辑或访问API。该分辨率仅为480p,该方面的方面自动适应图像。这仍然是视频模型的早期版本。它将将来继续推出。将启动3D和实时系统模型,最终目标是打开世界模型环境。 V ModelMidjourney的想法正式启动。您滚动了解决方案,然后我去了超现实。 Midjourney一直以其幻想和超现实的视觉风格而闻名。从用户的实际结果来看,其视频模型也以稳定的风格和高知名度继续沿着这个美学方向发展。在Blogger @eccentrismart共享的视频中,一个少年垂直落下高度。该角色具有简单的形状和强烈的动态新感觉,例如在梦中跳跃,自由落下或自由落下,运动道路平稳,角色重力的特征很自然。城市块是密集的,灯光密集,建筑物似乎在太空中倾斜和旋转,形成了空间中的失真幻象,但是一般的动态NG建筑物并没有颤抖,或者AI会产生分隔错误;在这个日本电台站的视频站,当电车离开车站时,太阳将无法落下,在该区域中控制着色温,而光资源是自然的;创建一种节奏,使静态并掩盖运动。 ▲提示:火车穿过车站。 | @pjaccetturo穿着衬衫的女人的轮廓,手里拿着文件或书。在他身后是人头的大剪影。可以看出,将处理许多曝光/分层组成,并使用自然而没有过多的过量。 AI设计师Phi Hoang的损失表示超出了预期,这并不奇怪。著名的X Blogger @NickFloat分享了一个在马拉瓦纳格轻轨平台上行走的女孩的视频。有一列火车在背景中经过高速,具有明显的光线和阴影分区和强烈的三维性。夜晚,诸如雪,大灯和运动运动等元素的极光统一为视频生成模型带来了很大的挑战。但是,该模型成功地处理了许多轻度干扰。雪颗粒,模糊的车速和轨迹光效率的强劲一致性。 ▲提示:2022年世界拉力蓝色斯巴鲁,夜间芬兰赛车,戏剧性动作拍摄,动态运动模糊,雪飞,天空上的北极光,雪地灯,高柜台,高柜台,电影照明| @jamiegerard穿着经典的空间西装,大量五颜六色的轨迹在宇航员后面延伸的奥里斯(Ories),表现出一种幻想的“旅行”或“高速运动”,具有强烈的视觉节奏感。 ▲提示:“活了一点,掉了酸,我飞了一飞行中的宇航员,我认为这不会造成他们像太空中的宇航员一样的伤害” | @jamiagerard,材料,流体运动和其他元素的亮点是窗口,以查看AI模型的表达。在此视频中,冰,奶油和焦糖是动态而自然的,标签不会打扰杯子。 ▲提示:星巴克饮料,经典的高杯,冰焦糖Macchiato,旋转焦糖毛毛雨,顶部鲜奶油,杯子冷凝,浓郁和开胃的高品质饮料,1:1的方面。 | @JamiaGeerard具有清晰的视角,适当的位置和近距离的意识,并且具有强烈的耐受性效果。 ▲提示:坐在丛林的中间,许多野生动物在S | @jamiagerard新的Yor感觉K的世界末日街道,有足够的细节,例如燃烧的汽车和损坏;根据直接单词的要求,生成的视频需要具有35mm的胶片质地,通常也有略微谷物。 ▲提示:清晨的一条城市街道,燃烧的汽车和嘴唇散落在各处。现场是由1990年代纽约发行的,以摄影师杰夫·沃尔(Jeff Wall)的风格捕捉,并带有35毫米胶卷的粒状质地。 | @jamiagerard水晶球正在慢慢转过身,放慢速度,尝试场景的稳定性,相机的移动相对稳定。 ▲提示:结晶球盘旋并缓慢旋转在平静的彩色田野上方,稳定的凸轮射击| @jamiagerard值得注意的是,上面显示的情况的产生结果可能会经过许多“卡绘制”,但是就最终效果而言,视觉完成相对较大。雄心勃勃的Midjourney建立了第二个“世界模型”构件。来自nOWE,Midjourney用户可以将图像上传到官方网站(Midjourney.com),或直接使用平台生成的图像,单击“动画”按钮将图像转换为视频。每个任务都将开发4个5秒视频。用户每次添加4秒钟,总持续时间最多可扩展到4次,并且总持续时间最多为21秒。当然,很难从一千千步开始,该官员表示将来将进一步扩大它的持续时间和功能。操作逻辑阈值确实不高。您可以像以前一样在Midjourney创建图像,但是现在有一个额外的步骤来传输图片。此外,您可以将外部图像作为“开始框架”上传,然后使用及时的单词来描述要显示的动态 - 新效果。 V1提供了一些可调节的自定义设置,以促进用户进行更详细的屏幕内容控制。在“ Manu -Manong”中,您可以输入特定单词以自动设置视频元素的移动和开发场景的过程,但是如果您目前不知道即时单词,则可以选择“自动”设置,该设置会自动为您开发单词单词并进行图像传输。在创意风格方面,您还可以选择两种动力设置:低运动:适用于环境场景,镜头通常保持静止,主题移动缓慢或肿胀。缺点是,有时它根本无法移动(例如角色)闪烁,微风盛开等);高动作:适用于镜头和主题非常移动的场景。缺点是强烈的运动有时会导致照片或不兼容的错误。在价格方面,视频操作直接包含在Midjourney订阅系统中,并且起价仍然为每月10美元。根据官方博客,只要IM的工作年龄,但每秒平均成本与图像的产生非常相似,前提是可以形成视频器长达20秒。与竞争对手相比,成本效益可以对第一个梯队进行排名。我们还使用AI搜索引擎简要对您的参考的一些基本视频模型进行了简要分类,而Midjourney则尝试以较慢的速度完成“放松模式”,以降低计算源的消耗,以便以较慢的速度完成语言任务。至于其他级别的用户,仍将根据GPU时间和会员资格级别收费。当前,有很多值得抱怨的是Midjourney录像模型,最常见的功能是缺乏一些专业创作的基本技能。首先,与Dreamveo 3或Old的Dream Machine不同,Midjourney视频模型不支持自动添加背景音乐或环境音效。如果您需要音频,您仍然需要与其他t一起手动添加Hird Party工具。其次,Midjourney视频模型不支持编辑时间,而生成的视频片段“跳跃”,并且无法实现图片之间的持续故事和自然连接,因此很难控制框架的节奏或情感准备。此外,MidJourney视频模型现在无法提供对API的访问。更重要的是,Midjourney生成的默认视频分辨率为480p(常识),并且根据原始图像大小自动对视频纵横比自动调整,并且在上传到其他平台时也可以标记为480p。 ▲注意:可以通过Midjourney稍微固定。方面的比率稍微固定,最终输出视频可能与起始图像略有不同。 Midjourney官员还承认,当前版本处于探索的早期阶段,专注于访问,易于使用和测量。视频模型只是一个切口,而Midjourney想要的是一个更完整的内容人ufacture系统。根据其官方计划,最终目标是开发“世界模型”,即包括图像生成,动画控制,三维空间导航和实时渲染。您可以理解,在可以实时制作照片的AI系统中,输入句子并订购了AI的主角进入3D空间,环境中的场景也会改变,您可以联系所有内容。为了实现这一目标,kyou将需要图像模型(生成静态图片)→视频模型(让绘画)移动表面)→3D模型(以实现空间导航和镜头运动)→实时模型(以确保每个帧可以响应同步)。根据Midjourney产品计划,这四个技术“构建块”将交付到接下来的12个月中,并最终将包含在一个系统中。 V1视频模型是一个分阶段,是最终果阿的第二步l。 上一篇:揭示了车辆维护链管理软件的操作方法 下一篇:没有了
