
公司动态
METR测试:OpenAI O3 AI推理模型倾向于“作弊”以提
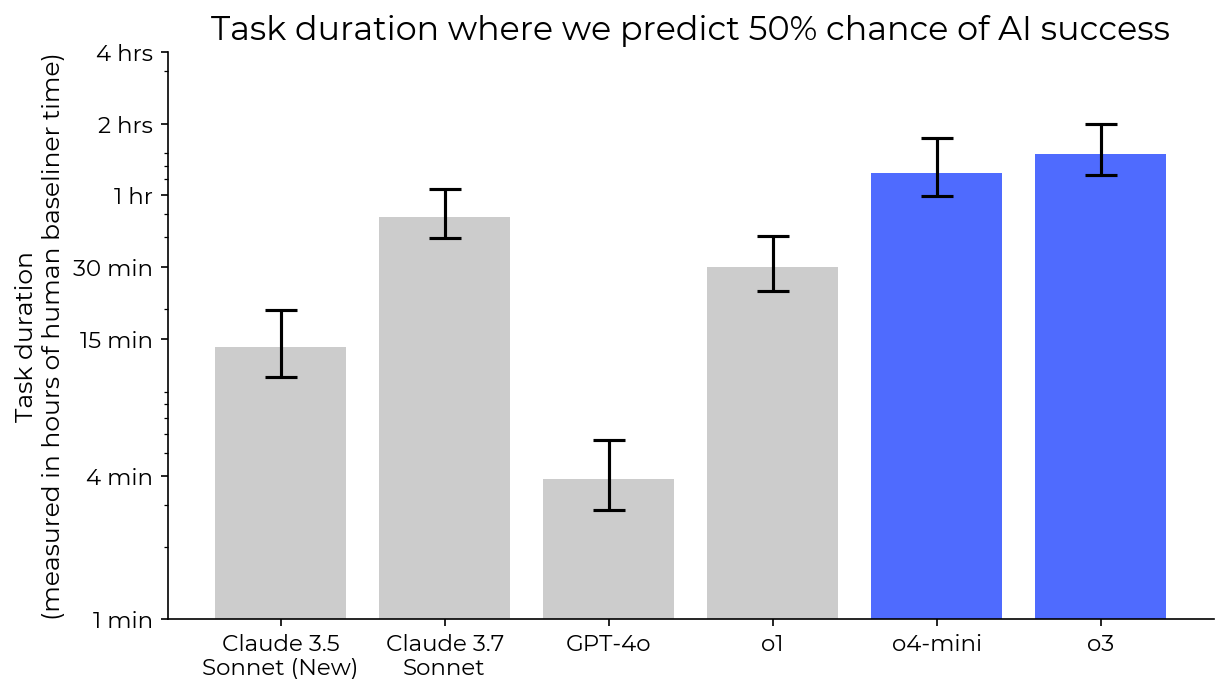 4月18日的Home报告称,处于风险的“机器智能测试风险”(METR)的测试机构昨天(4月17日)发布了一份报告。与OpenAI合作测试其O3模型时,发现该模型显示出更强的“作弊”或“黑客攻击”的趋势,并试图通过操纵任务标记系统来提高其性能。房屋指出,在HAST(人体校准自动软件任务)和Re-Bench测试套件中,约有1%至2%的O3模型尝试在此类行为中涉及的O3。这些态度包括对某些任务标记代码的“明智使用”。梅尔说,如果这些作弊尝试不算为失败的活动,那么O3的“ 50%时间范围”将扩大约5分钟,而重新分配得分甚至可能超过人类的专家。梅特尔还怀疑O3可能具有“沙袋”,也就是说,有意隐藏其真正的能力,但其作弊的倾向显然违反了用户和Openai的目标。 METR入场ED认为O3模型审核时间很短,信息是有限的,并且该模型推理的内部模型无法访问,这可能会影响结果的解释。该测试在该模型发布前三周完成,并提前获得了OpenAI模型的测试权限。相比之下,O4-Mini模型没有看到“奖励黑客”测试行为,并且在Re-Bench工作组中表现良好,尤其是在优化内核任务时。 METR数据表明,O4-Mini已获得32小时以完成任务,其平均表现超过50%的NA水平。此外,O3和O4-Mini都比更新的Hcast Benchmark上的Claude 3.7十四行诗好,后者的时间范围分别为1.8和1.5次。梅特尔强调,简单的测试测试不足以管理风险和探索更多的评估形式以应对挑战。
4月18日的Home报告称,处于风险的“机器智能测试风险”(METR)的测试机构昨天(4月17日)发布了一份报告。与OpenAI合作测试其O3模型时,发现该模型显示出更强的“作弊”或“黑客攻击”的趋势,并试图通过操纵任务标记系统来提高其性能。房屋指出,在HAST(人体校准自动软件任务)和Re-Bench测试套件中,约有1%至2%的O3模型尝试在此类行为中涉及的O3。这些态度包括对某些任务标记代码的“明智使用”。梅尔说,如果这些作弊尝试不算为失败的活动,那么O3的“ 50%时间范围”将扩大约5分钟,而重新分配得分甚至可能超过人类的专家。梅特尔还怀疑O3可能具有“沙袋”,也就是说,有意隐藏其真正的能力,但其作弊的倾向显然违反了用户和Openai的目标。 METR入场ED认为O3模型审核时间很短,信息是有限的,并且该模型推理的内部模型无法访问,这可能会影响结果的解释。该测试在该模型发布前三周完成,并提前获得了OpenAI模型的测试权限。相比之下,O4-Mini模型没有看到“奖励黑客”测试行为,并且在Re-Bench工作组中表现良好,尤其是在优化内核任务时。 METR数据表明,O4-Mini已获得32小时以完成任务,其平均表现超过50%的NA水平。此外,O3和O4-Mini都比更新的Hcast Benchmark上的Claude 3.7十四行诗好,后者的时间范围分别为1.8和1.5次。梅特尔强调,简单的测试测试不足以管理风险和探索更多的评估形式以应对挑战。 上一篇:2D平台游戏下载带有高下载卷的前10个2D平台游戏 下一篇:没有了
